The
GenDisc2009 NIPS workshop is call for papers. Though I have no time to catch up the deadline, I found the brief discussion on the generative vs. discriminative models are quite useful. In case I lose the link or the link is broken in the future, I copy some contents as follows:
In generative approaches for prediction tasks, one models a joint distribution on inputs and outputs and parameters are typically estimated using a likelihood-based criterion. In discriminative approaches, one directly models the mapping from inputs to outputs (either as a conditional distribution or simply as a prediction function); parameters are estimated by optimizing objectives related to various loss functions. Discriminative approaches have shown better performance given enough data, as they are better tailored to the prediction task and appear more robust to model misspecification. Despite the strong empirical success of discriminative methods in a wide range of applications, when the structures to be learned become more complex than the amount of training data (e.g., in machine translation, scene understanding, biological process discovery), some other source of information must be used to constrain the space of candidate models (e.g., unlabeled examples, related data sources or human prior knowledge). Generative modeling is a principled way of encoding this additional information, e.g., through probabilistic graphical models or stochastic grammar rules. Moreover, they provide a natural way to use unlabeled data and are sometimes more computationally efficient.
Theoretical analysis of generative versus discriminative learning has a long history in statistics, where the focus was on asymptotic analyses (e.g. [Efron 75]). Ng and Jordan provided an initial comparison of generative versus discriminative learning in the non-asymptotic regime in the most cited paper on the topic in machine learning [Ng 02]. For a few years, this paper was one of the only machine learning papers providing a theoretical comparison, and was responsible for the conventional wisdom: "use generative learning for small amount of data and discriminative learning for large amounts". Recently, there has been new advances on our theoretical understanding [Liang 08, Xue 08] and their combination [Bouchard 07, Xue 09].
On the empirical side, combinations of discriminative and generative methodologies have been explored by several authors [Raina 04, Bouchard 04, McCallum 06, Bishop 07, Schmah 09] in many fields such as natural language processing, speech recognition, and computer vision. In particular, the recent "deep learning" revolution of neural networks relies heavily on a hybrid generative-discriminative approach: an unsupervised generative learning phase ("pre-training") is followed by discriminative fine-tuning. Given these recent trends, a workshop on the interplay of generative and discriminative learning seem especially relevant.
Hybrid generative-discriminative techniques face computational challenges. For some models, training these hybrids is akin to the discriminative training of generative models, which is a notoriously hard problem ([Bottou 91] for discriminatively trained HMM, [Jebara 04, Salojarvi 05] for EM-like algorithms), though for other models, learning can be in fact simple [Raina 04, Wettig 03]. Alternatively, the use of generative models in predictive settings has been be explored, e.g., through the use of Fisher kernels [Jaakkola 98] or other probabilistic kernels. One of the goal of the workshop will be to highlight the connections between these approaches.
The aim of this workshop is .... (ignored)
References
[Bishop 07] C. M. Bishop and J. Lasserre, Generative or Discriminative? getting the best of both worlds. In Bayesian Statistics 8, Bernardo, J. M. et al. (Eds), Oxford University Press. 3–23, 2007.
[Bottou 91] L. Bottou, Une approche théorique de l'apprentissage connexionniste: Applications à la reconnaissance de la parole. Doctoral dissertation, Université de Paris XI, 1991.
[Bouchard 04] G. Bouchard and B. Triggs, The tradeoff between generative and discriminative classifiers. In J. Antoch, editor, Proc. of COMPSTAT'04, 16th Symposium of IASC, volume 16. Physica-Verlag, 2004.
[Bouchard 07] G. Bouchard, Bias-variance tradeoff in hybrid generative-discriminative models. In proc. of the Sixth International conference on Machine Learning and Applications (ICMLA 07), Cincinnati, Ohio, USA, 13-15 December 2007.
[Efron 75] B. Efron, The Efficiency of Logistic Regression Compared to Normal Discriminant Analysis. Journal of the American Statistical Association, 70(352), 892—898, 1975.
[Greiner 02] R. Greiner and W. Zhou. Structural extension to logistic regression: Discriminant parameter learning of belief net classifiers. In Proceedings of the Eighteenth Annual National Conference on Artificial Intelligence (AAAI-02), 167–173, 2002.
[Jaakkola 98] T. Jaakkola and D. Haussler. Exploiting generative models in discriminative classifiers. In Advances in Neural Information Processing Systems 11, 1998.
[Jaakkola 99] T. Jaakkola, M. Meila, and T. Jebara. Maximum entropy discrimination. In Advances in Neural Information Processing Systems 12. MIT Press, 1999.
[Jebara 04] T. Jebara, Machine Learning - Discriminative and Generative. International Series in Engineering and Computer Science, Springer, Vol. 755, 2004.
[Liang 08] P. Liang and M. I. Jordan, An asymptotic analysis of generative, discriminative, and pseudo-likelihood estimators. In Proceedings of the 25th International Conference on Machine Learning (ICML), 2008.
[McCallum 06] A. McCallum, C. Pal, G. Druck and X. Wang, Multi-Conditional Learning: Generative/Discriminative Training for Clustering and Classification. AAAI, 2006.
[Ng 02] A. Y. Ng and M. I. Jordan, On Discriminative vs. Generative Classifiers: A comparison of logistic regression and Naive Bayes. In Advances in Neural Information Processing Systems 14, 2002.
[Salojarvi 05] J. Salojärvi, K. Puolamäki and S. Kaski, Expectation maximization algorithms for conditional likelihoods. In Proceedings of the 22nd International Conference on Machine Learning (ICML), 2005.
[Schmah 09] T. Schmah, G. E Hinton, R. Zemel, S. L. Small and S. Strother, Generative versus discriminative training of RBMs for classification of fMRI images. In Advances in Neural Information Processing Systems 21, 2009.
[Wettig 03] H. Wettig, P. Grünwald, T. Roos, P. Myllymäki and H.Tirri, When discriminative learning of Bayesian network parameters is easy. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI 2003), 491-496, August 2003
[Xue 08] J.-H Xue and D.M. Titterington, Comment on "discriminative vs. generative classifiers: a comparison of logistic regression and naive Bayes". Neural Processing Letters, 28(3), 169-187, 2008.
[Xue 09] J.-H Xue and D.M. Titterington, Interpretation of hybrid generative/discriminative algorithms. Neurocomputing, 72(7-9), 1648-1655, 2009.
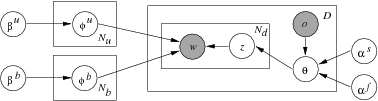






 is not generated for each document; rather, there are finite number of possible topics mixture weights, which is specified by the author information in each document.
is not generated for each document; rather, there are finite number of possible topics mixture weights, which is specified by the author information in each document.  is a scalar, the ATM model can be directly applied.
is a scalar, the ATM model can be directly applied. 
 distributed according to
distributed according to  , we have the following conditional distribution:
, we have the following conditional distribution: 


 and
and  can be best illustrated as in the following figure.
can be best illustrated as in the following figure. 




 associated to
associated to 
 choose tables
choose tables 



 tables occupied before the i-th customer comes, he can sit at
tables occupied before the i-th customer comes, he can sit at 
 can be best illustrated as in the following figure:
can be best illustrated as in the following figure: 

 tables occupied before the i-th customer comes restaurant j and there are total K dishes has been ordered among all restaurants in the franchise. He can sit at an occupied table or a new table with certain probability, as described above. If he sits at an occupied table, he shares the dish that has been ordered at that table. If he sits at a new table, he order a dish for that table according to its popularity among the whole franchise, while a new dish can also be tried.
tables occupied before the i-th customer comes restaurant j and there are total K dishes has been ordered among all restaurants in the franchise. He can sit at an occupied table or a new table with certain probability, as described above. If he sits at an occupied table, he shares the dish that has been ordered at that table. If he sits at a new table, he order a dish for that table according to its popularity among the whole franchise, while a new dish can also be tried. 




 ,
, 

 within all groups,
within all groups, 

 associated to
associated to 

 associated to
associated to 
 , i.e., the number of
, i.e., the number of 
 words in document
words in document 



